42. |
Looking at the data (Galasso: 1999),
we indeed find a strong correlation between SAS strings and
mixed word order alongside DAS strings and fixed order.
Table 5 Word Order
| Files:
8-16 SAS |
SV |
VS |
DAS=
SVX / Other |
| Age:
2;4-2;8 n.= |
87 |
78 |
290
5 |
I. Some token examples include:
(a) SV: Daddy cooking. Him go
(b) OV: Dog kick (= I kick dog). A egg cook. (= I cook egg).
(c) VS: Open me (= I open). Work bike (=Bike works)
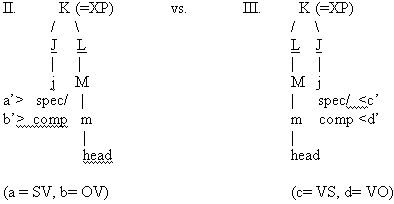
In terms of structure, before on the onset of DASs, a Proto
XP could be assigned to our SAS stage providing the variable
word orderings:
|
|
43. |
In addition to general word order variability,
Wh-word order patterns emerge in our early files (age 2;4-3;0)
showing semi-formulaic consistencies when examined in light
of the general acquisition of complex structureas mentioned
above regarding SAS vs. DAS complexity. Our data evidence
a pattern showing Non CSV (Non Comp Subject Verb) ordering
which could be interpreted as formulaic in nature. This stage
roughly overlaps with our SAS stage mentioned above. Like
Kayne on Word order, Cinque (1990) has formulated a strong
universal position claiming that all Wh-elements universally
position within the Spec-of-CP. Recall, that CP is a functional
category that should have a delayed onset time under any maturational
theory (cf. Radford: 1990). Here too we need to weaken the
strong position by adding the stipulation that in order for
this Spec-CP analysis to hold, the subject must simultaneously
surface forcing the Wh-element to raise and preposition in
Spec-CP. Otherwise, very early (stage-1) Wh-arguments (e.g.,
What, Who) seemingly get initially misanalyzed as base-generated
3Person Pronoun/Quantifiers placed in superficial subject
Spec-VP position. This miscategorization often results in
Agreement errors where the Wh-word, seen as incorrectly taking
the thematic-role of the subject, agrees (by default) with
the verb. Consider the structures of the two following CP-
structures below:
Table 6 Wh-word
order
|
Non
CSV |
Wh
Spec-CP (CSV) |
| Files
1-21 n.= |
78 |
0 |
| Files
22-25 n.= |
120 |
80 |
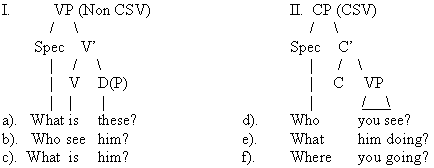
|
|
44. |
In sum, arguments could be devised suggesting
that early Wh-structures are prime examples of semi-formulaic
strings base generated (VP insitu). A later second
stage (or even overlapping stage) may thus be seen as converting
formulaic processes into rule driven processes whereby syntactic
manifestations of Wh-movement occur with or without Auxiliary
inversions. (See Stromswold (§6) above for Non-Aux inversions).
Regarding formulaicy, Pine & Lieven (1997), Pine et
al. (1998) claim that a non-rule based account is what
is behind the formation of early correct wh-questions (a U-shape
learning take on the data). While adopting a constructivist
account in explaining the high rate of correctly inverted
Wh + Aux combinations, they go on to predicted that correctly
inverted questions in a the childs stage-1 data would be
produced by those wh + aux combinations that had occurred
with high frequency in the childs input. They go on to specify
that there is evidence that the earliest wh-questions produced
with an Aux. can be explained with reference to three formulaic
patterns that begin with a limited range of wh-word + aux.
Combinations (e.g., whydont you/she) (Rowland &
Pine, 2000). Such findings on early formulaic structures parallel
what Tomasello (1992) and Newport (op. cit.)
suggest regarding an initial stage-1 that reflects a processing
deficit tied to functional grammar. In other words, child
stage-1 processing which shows a bias toward the modeled high
frequency lexical input (vs. rule driven analogy) may
arise due to constraints imposed by the low memory bottle-neck
of distributional learning (Braine 1987, 1988)
|
|
| |
Lexical Stage-1: A Recap
|
| 45. |
In light of the above data, and the collections
of data elsewhere, it could be argued for our stage-1 that
the childs utterances involve pure projections of thematic
argument relations. In Minimalist terms, the operation Merge
would directly reflect thematic properties and that this operation
is innately given by the Language Faculty: Verbs directly
theta-mark their arguments as in predicate logic expressions:
Table 7 Argument/Predicate Structure
| Token Utterance: |
(d)addy work |
(m)ommy see daddy |
| Predicate Logic: |
work(d) |
see(m,d) |
The above Word Order/Syntax includes (SV) and (SVO) patterns
and is structured below:
[vP[N Dad][[v0][VP[V work]]] [vP [N Mom][[v0][VP
[V see][N dad]]]]
(vP=light-verb Phrase).
|
|
| 46. |
In both example above, the Nouns (Daddy
& Mommy) contain no formal features (such as person
or case) and so dont agree with the verb. The verb likewise
carries no Tense or Agreement features. In this sense, theta-marking
directly maps onto the semantics of lexical word classesviz.,
pure merger involves only theta-marked lexical items. It is
therefore claimed that there is no Indirect theta-marking capacity
at stage-1 such that oblique or prepositional markers would
enter into the syntax: for example, the PP to work in Daddy
goes to work, would be thematically reduced in the operation
Merge as Daddy go work (work =Nouns and not infinitive
verb). Such utterances are wide spread for our stage-1 as was
revealed in the section above. In addition to seemingly direct
thematic based syntax/grammar, numerous other studies have shown
that, indeed, children inappropriately overextend semantic (causative)
alternations of verbs such as giggle vs. tickle
by indiscriminately giving them identical thematic argument
structures Thematic role Patient in their intransitive forms:
e.g., dont giggle me! vs. dont tickle me! (Bowerman,
1973). If we wish to make claims that such overgeneralizations
are a result of some innate linking rule, then clearly some
sort of default semantic-based linking rule must be up for discussion.
In any event, the lack of non-semantic [-Interpretable] formal
features certainly dispels the notion of syntax and leads us
to look at such early stage-1 lexical items as being stripped
of their formal features, and projecting quasi-semantic information
on a class of their own-perhaps to the point that each lexical
item is learned and projected in isolation
|
|
| 47. |
In conjunction to an isolative lexicon, and much
in the same spirit with Pine et al. above, Morris et al. (ms
1999) has sketched out a theoretical proposal (based on PDP-style
connectionism) that relegates verb-argument structures in childrens
stage-1 grammar to individual min-grammars-that is, each word
is learned (bottom-up) in isolation in that there are no overarching
abstractions (top-down) that link one verbs argument
structure to another. In other words, there are no argument
rules, only isolated word meanings-each argument structure
is a separate grammar unto itself (p. 6). It is only at
a second stage-2 that the child is seen as corresponding the
semantic as well as the syntax over from one word to another.
For example, the verbs eat and drink, hit
and kick, etc. will merge at stage-2 in ways that will
project this overarching abstract structure regarding transitivity,
thematic structure, etc. Hence, stage-2 is defined as the benchmark
in emergence of true syntax and rule formation.
|
|
| 48. |
In sum, what the above sketch has to offer us
is the proposal that children start off (stage-1) with rote-learned
items and then strive to find commonalitiesthe child then builds-up
this lexicon from brute memory and only later (stage-2) does
she slowly start to form levels of abstraction. The claim is
that children learn grammatical relations over timethe bottom-up
processes mimic the maturational processes behind language acquisition
(viz., first a stage-1 bottom-up lexical learning followed
by a stage-2 top-down rule formation).
|
|
| 49. |
Insert Interpretable features Radford here
|
| 50. |
Distributional Morphology. A second
but similar line of reasoning, likewise motivated by outcomes
in Chomskys Minimalist Program (see Marantz 1995, 1997) calls
for morphology to be the all encompassing aspect of grammardoing
away all together with the lexicon as maintained under so call
lexicalist hypotheses, as well as dispensing, to a certain
degree, with traditional notions of syntax that sought to derive
a syntactic model outside of the lexicon in a seemingly top-down
manner. The theorys basic core calls on a number of assumptions:
viz., (i) that syntactic hierarchical structures resonant all
the way down to the word (or perhaps more accurately described
as being essentially derived from the word); (ii) that the
notion of word is broken up into two properties the word
shell of phonology, (or as it is termed in DM, the Idiom), and
the words selectional morphological features. The distinctions
are articulated in terms of morphology by the following labeling:
the l-morphemewhich pertains to the idiom aspect of the sound-meaning
relationand the f-morphemewhich correlates to the abstract
morphological features. These two labels may be seen as correlating
to Radfords usage of +/-Interpretable features (above) where
the [+Interp] feature distinction pertains to lexical items
semantic properties (part of which would be the Idiomatic aspect
of the word as used in DM, along with its phonological make-up
(i.e., l-morpheme), and where [-Interp] would correlate to
the more formal and abstract syntactic properties (i.e., the
f-morpheme). The two-prong theory today is seen as part and
parcel of a formal language system. Traditional parts of speech
such as Noun are redefined as a bundle of features that make-up
a single l-morpheme type (called Root). The Noun root or l-morpheme
is defined by how the root entertains certain local relations
or governing conditions which it imposes on its complement hostse.g.,
how the Noun root might c-command or license its Determiner
(in a local Specifier position) or a Verb (in a local Complement
position). A classic example here would be how the same lexical
item Destroy appears as a noun Destru(ction) when
its nearest adjacent licenser is a Determiner (The destruction),
or how the item takes on the role of a verb when its nearest
adjacent licensers are Tense/Agreement and Aspect ( Destroy-(s),
(is) destroy-ing, (have) destroy-ed) (marking Tense, and
Participle respectively). This model now places the burden of
syntax not with exterior stipulations, but rather with interior
conditions that seem to flow up-ward from the lexical items
itself and into the relevant projecting phrase. In this new
definition (taken right out of MP, Bare Phrase Structure),
the phrase is reorganized as simply the sum of the total interacting
f-morpheme parts; the word; is thus redefined as nothing
more than a buddle-of-features that project out of the phonological
shell. This new analysis will hold a number of consequences
for how we come to understand language acquisition. For starters,
much of what is being spelled out here concerns a two-stage
acquisition of language development and that this dual stage
can be accounted for the dual mechanism model as advanced in
this paper. What I am on about here can be summarized as follows
regarding language acquisition:
(i) Syntax, as understood in Chomskys Pre-Minimalists
terms, may for all intents and purposes reduce to specific
bundle-of-features that are encoded in parts-of-speech
words, (rendering a seemingly bottom-up learning mechanism
where meaning governs not only how words are learned,
but how their syntactic properties project).
(ii) Syntax may no longer be considered as a top-down generator
of sentence types, and so words have the capacity to emerge
in a early stage of language merely encoded with l-morphology
or [+Interp] features. In this way, one may be able to define
an early stage-1 word as exhibiting more or less only the
phonological shell of the word void of its otherwise embedded
syntax. If this is indeed the case, a viable maturational
story can likewise hold for the onsets of f-morphology
[-Interp] features for the given word. Much in the manner
of Roger Browns observation leading to a sequence of morphological
development (staring with -ing and ending with the
Aux. Clitic etc.), a similar story could likewise
hold regarding how certain features mature and then merge
in a worda maturation of features however which would not
delay the onset of the word in phonological terms (or l-morpheme
values), but would only delay the relevant selectional properties
(or f-morpheme values, etc.) associated with its functional
grammar.
The twin notions above would ultimately buttress any theory
which would see language development as a maturational interplay
of featuresas captured here in our discussion of a Converging
Theories Model.
|
|
| 51. |
--Insert DP-analysis stage-1 here
|
| |
| 52. |
A typical Chomskyan syntactic tree asserts
that functional features (features having to do with M(ood),
T(ense) and Agr(eement)) are assumed to be projected in a
top-down way: these functional features are understood to
be what is behind the notion of movementlexical items move
up the tree in order to acquire and check-off these features.
The following question certainly could be formulated in Chomskyan
terms: why cant lexical items have such features embedded
in their sub-categorical entries, and if they can, what then
would motivate movement other than some ad hoc stipulation
requiring features to be checked-off in a overall top-down
environment? Chomskys interpretations are clear heresome
top-down (deductive) measure must be constructed in order
to establish a proper rule-driven syntax. Well, this may in
all likelihood be correct, but where/what is it in the system
that says that the syntax must start out in this way. Consider
the tree below (reduced showing only M & T/Agr features):
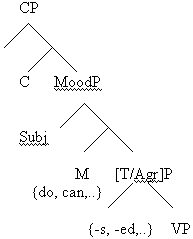
The tree above positions the T/Agr features,
along with their specific phrases, as having a top-down representation.
If such a tree is completely available early-on in language
acquisitionas the Continuity view would maintainthan there
should be no reason why a child would exhibit 100% omission
of say a top-down Agr feature in the way that would affect
only certain words and not others. (When only certain words
show individual residual affects, e.g., regarding subcategorization,
syntax etc., then a strong claim can be made that the overarching
phrase structure is not what is behind the phenomenon, but
rather specific lexical-parameterizations may be involved.)
(See J. Fodor 1997, Baker 2002 for a seemingly bottom-up treatment
of lexical parameterization). In other words, if the structure
is in place (from top-down) to deliver the feature of Agr
(as with Case), than it would be hard to explain away the
fact, if observed in the data, that some words could maintain
Case while others (which should maintain Case in the target
language) do not. Guasti and Rizzi (2001) say: When a feature
is not checked in the overt syntax UG makes it possible to
leave its morphological realization fluctuating. Fine. But,
this is seemingly a bottom-up problem. It seems that such
optionality would have nothing to do with the phrase (per
se). What do we say when the feature itself (as projected
from the tree top-down) seems to select some words over others
regarding inflection? Surely, if this is a top-down venture,
then the features should project onto all verbs (for the appropriate
phrase), and not just a select few. But this is in fact what
we find at our stage-2 of language developmentsome words
may (optionally) inflect/project the specific feature while
others completely by-pass it (entirely).
|
|
| 53. |
--Insert data from Radford & Galasso here--
|
| |
| 54. |
This gives us the flavor of specific words
(and not word classes) taking on functional features (bottom-up).
The problem here is how does one maintain the higher-ordinance
structure of functional grammar originating from the latter
two upper layers of the tree while selecting the functional
projection on only a select handful of words. One way around
the dilemma may be to suggest that the lexical word itself
has part of the (upper-branching) tree embedded in the very
lexical item itself (as in sub-categorization). In this way,
a specific word may reflect a specific functional feature
or parameter while another word may not (on a specific lexeme
by lexeme basis)in all actuality, what we are talking about
here is that (i) the initial process of the acquisition of
functional grammar involves one word at a time (in a bottom-up
way), and that (ii) only at a later more developed stage does
such feature projection extend to the overall class of words
(which then extent to phrases). Following in the spirit of
Lexical Parameterization (Borer), Janet Dean Fodor
in a similar vain has tentatively suggested in some recent
work that parameterization may affect certain words (as in
lexical feature specificity) and not others (outside of the
scope of its word class) (talk presented at the University
of Essex, 1997). One outcome of this would assume that children
establish parameter values (perhaps piece-meal) and not grammars
as wholes. An example of such bottom-up parameterization or
say feature specificity (only selecting [+/-Nom] Case marking
here) might then be diagrammed in the following manner:
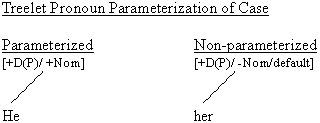
Such an exclusively bottom-up parameterization
method would however obscure correlations often found in the
data regarding Case and/or Agreementsuch as a seemingly top-down
holistic correlation which seeks to link (i) [+Nom] Case if
in an agreement relation with a Verbal INFL, (ii) [+Gen] Case
if in an agreement relation with a nominal INFL, (iii) Default
Case otherwise. It may be that such correlations do come on-line
after an initial non-phrase parameterization stagehence,
an initial and not fully fledged parameterized stage would
meagerly work with individual words, delaying class-parameterization
to a slightly later stage.
|
|
| 55. |
A growing body of research recently undertaken
by developmental linguistics suggests that childrens (stage-1)
multi-word speech may in fact reflect low-scope lexical specific
knowledge rather than abstract categorical-based knowledge.
As discussed above, this distinction clearly points to a possible
language acquisition processes as proceeding from out of a dual
mechanism in the brain. For example, regarding verb inflection,
studies (Tomasello & Olguin, Olguin & Tomasello, Pine
& Rowland) have shown that the control children have over
morphological inflection very early in the multi-word stage
is largely individually rote learnedthat is, there is no systematic
relationship between stem and inflection, nor is there any transfer
from supposed knowledge of an infection to other stems. In
other words, at the very earliest stages of multi-word speech,
there is little or no productively of transferring the knowledge
of one verb to another. This may suggest a stage-1 based not
on complete paradigm formation, but rather on (semi)-formulaicy.
|
|
| 56. |
Rowland suggests that a distributional learning
mechanism capable of learning and reproducing the lexical-specific
patterns that are modeled in the input may be able to account
for much of what we find in the early stage-1 data. Input of
a high frequency nature will then trigger rote learning associations
and patterns that will manifest in the speech production of
young children. This notion of rote-learned vs. rule-based
or non-systematic vs. systematic behavior (respectively) can
be further investigated by looking into what has become known
as the U-shape learning curve. For instance, indications
of systematic (rule-based) behaviors can be seen in overgeneralization.
In other words, if overgeneralizations appear with, say, the
morphological inflection {s} as in the portmanteau forms for
either Verb or Noune.g., I walk-s, feet-s (respectively),
than a sound argument could be made that rules have been employed-albeit,
rules which have erroneously over-generated. (In fact, if children
in the process of their early language acquisition are never
seen to over-generalize rule-like formations, this is very often
a sign of potential Specific Language Impairment (SLI), a result
of some neo-cortical brain malfunction which has disturbed the
normal syntactic structuring of rules and paradigms.) And so,
we rightly extend the argument that if rules are being applied
at a given stage, than a rule-based grammar has been activated:
Right you say. Well, as it turns out, there are some very interesting
findings which suggest that apparent look-a-like rules at
stage-1 are in fact imposters and dont really behave as true
rules.
|
|
| 57. |
U-Shaped Learning. One of the most
striking features of language acquisition is the apparent
so called U-shaped Learning Curve found straddling
the two stages of language acquisition. In brief, the U-shaped
curve is understood in the following way:
(i)Inflection. Childrens earliest Inflected/Derivational
word types are, in fact, initially correct-that is, it appears
to be the case amongst very early MLU that children have
correct formulation of rules. (It goes without saying that
typical early MLU utterances indeed have no tense markings
to speak of (cf. Wexler & Radfords Maturational Theory).
The point here is that whenever a small sampling of Tense
does appear in early MLU speech, it always appears correctly).
An example of this is the early emergence in the data of
the past tense and participle affixes [ed] and [en] e.g.,
talked/gone (respectively). The initial Past Tense
and Plural forms are correct, regardless of whether or not
these forms are regular (talked/books) or irregular (went/sheep).
However, and what is at the heart of this striking development,
it also appears that this initially correct performance
stage is then followed by a period of attrition during which
the children actually regressthat is, at this slightly
later stage in development, they do not only lose some forms
of affixation, but in addition, produce incorrect over-generalizations
in tense forms (go>goed>wented), and plural
forms (sheeps), as well as non-inflected tensed forms
e.g., talk-ø/go-ø (=past tense). To recap, the first
occurrence of inflectional overgeneralization roughly at
age 2 years that supports a rule-based grammar is preceded
by a phase without any errors at all.
(ii)Phonology. Similar to what one observes regarding
a u-shape grammatical/inflectional development, children
also appear to follow a u-shape learning curve with regards
to phonology. An example of this is the often cited early
productions of e.g., (i) slept /slept/, cooked
/kƯkt/, played /plae:d/ > to (ii) sleeped
/slipId/, cooked /kƯkId/, played /plae:Id/
> and back to (iii) slept /slept/, cooked
/kƯkt/, played /plae:d/ (respectively) completing
a
U-shaped morpho-phonetic curve yielding /t//d//t//d/.
What appears to be good examples of rule-based inflection
and assimilation in (i) and (ii) (above respectively) is
in all actuality nothing more than the product of a parrot-like
imitation sequencemore akin to iconic pattern processing
derived from stimulus and response learning. The child can
be said to engage in segmental, phonetic-based rules only
when s/he appears to process the rules yielding an incorrect
overgeneralization of past marker {ed} typically pronounced
as the default /Id/ which forms the middle-dip portion of
the u-shape curve. Recall, in terms of phonology, the child
has three allophonic variations to chose from:
a. {ed} => /t/ walked /wa:kt/
b.& {ed} => /d/ played /ple:d/
c. {ed} => /Id/ wanted /wantId/
It seems that a default setting with regards to phonology
(place & manner of articulation) is minus Comp(lex) where
[-Comp] denotes one feature distinction over a two or more
features (for instance, bilabials /b/ /m/ would have a [-Comp]
feature whereas labio-dentals and inter-dental /f/ /q/ (respectively)
would have a [+Comp] since both lip and tooth are involved.
In addition, it seems that plus voicing [+V] typically wins
out over minus voicing [-V]. By using these default settings,
we naturally get voiced plosive /b/ d/ /g/, nasals /m/ /n/,
as our very first sequence of consonants along with [+V] vowels.
By taking this default status, the /Id/ should be the allophone
of choice, and it often is. In this manner of speaking, adherence
to the default setting suggests at least some formation of
the rule: defaults work within rule-based paradigms and so
should be considered as a quasi-rule-based generation as opposed
to a pure imitation sequence.
|
|
| 58. |
The first two stages of development that form
this apparent u-shape curve has been interpreted as manifesting
the application of qualitatively different processes in the
brainrepresenting different modes or stages in the course
of language acquisition. This u-shaped curve arguably provides
some support for our stage-1 to be defined in terms of a formulaic
stage rather than as a syntactic and true-rule learning stage.
The second up-side of the u-shaped curve is found to coincide
with an independent syntactic developmentthe emergence of
a Finiteness marker, and that this finiteness marker only
emerges at our functional stage-2 (see Clahsen). In sum, the
three stages could be described in the following way:
(i) The first period of the first up-side curve (correct
production) correlates with a style of rote-learning. This
more primitive mode of learning suggests that the mental lexicon
is bootstrapped by mere behaviorist-associative means of learning.
In such a rote-learning stage, lexical items (either regular
or irregular inflections) are stored in an independent mental
lexical heavily based on memorization of formulaic chunks
and associations and are processed in a different part of
the brain. It is of no surprise that irregular verb past inflection
(go>went) out number regular verb past inflection
(talk>talk-ed): The former being stored in the lexicon
as a formulaic chunk, while the latter indicating the morphological
rule formation [V+ {ed}]. Hence, our dual converging theories
model postulates for a sharp contrast and disassociation between
regular vs. irregular inflection. This seemingly early correct
production is therefore due to a low-scope, phonological one-to-one
& sound-to-meaning relationship with no relevance to
rules. Hence, our formulaic past tense inflection is
not realized as [stem + affix] [talk-{ed}], but rather
as one unanalyzable chunk [talked].
(ii) The second stage then marks the onset of a rule
process (albeit, not necessarily the mastery of it). Here,
the child is seen as letting go with the formulaic lexical
representation in favor of rule formations: i.e., patterns
of concatenate stems appear along side inflectional affixes.
Thus, irregular forms often get over-generalized with the
application of the rule resulting in e.g., goed/wented/sheeps.
This overgeneralization stage maps onto a chronological
functional categorical stage of language acquisition where
rule-based mechanisms are becoming operative. Thus, the over-generalized
up-swing of the u-shaped curve is linked to childrens syntactic
development: over-generalization of inflection appears when
the child ceases using bare-stems (as in stage-1) to refer
to past events.
(iii) The third and final stage marks the second up-side
swing of the u-shaped curve and represents the correct target
grammar.
|
|
| 59. |
It is thus proposed that this tri-staged learning
processfrom correct to incorrect to correct againcan more
properly be accounted for by a dual learning mechanism in the
brain: (i) an initial mechanism that has no bearing on rules
and is pinned to a type of process best suited for more behavioristic
associative learning, such as base lexical learning, irregular
verb learning, lexical redundancy formations, etc
|
|
| |
Brain Related Studies
|
| 60. |
Much of the theory behind a dual model of language
has become buttressed by recent developments in Brain Related
studies. There is now an ongoing stream of data coming in that
tells us the brain does indeed process different linguistic
input in very different ways. Some of the first analyses using
fMRI (functional Magnetic Resonance Imaging), and other brain-related
measures show that irregular inflection processes (go>went)
seem to be located and produced in the temporal lobe/motor strip
area of the brain, a processing area strictly associated with
basic word learning referred to as the lexical component,
or Lexicon). On the other hand, regular inflection processes
e.g., (stop>stopped), where the rule [stem]+[affix]
is applied, point to areas of the brain which generate rule
formations, i.e., the computational component. In other
words, there seems to be a clear indication that the two types
of linguistic processes are dissociated. This same disassociation
seems to project between how one processes derivational morphologyhere,
being equated to irregular and/or whole lexical word retrievaland
inflectional morphology.
|
|
| 61. |
Wakefield and Wilcox (=W&W) (1994: 643-654)
have recently concluded that a discontinuity theoryalong the
lines proposed by Radfordmay have an actual physiological reality
as based on a biological maturation of brain development.
Their work consists of two segments: the first being a theory
of the relationship between certain aspects of brain maturation
and certain transitions in grammatical representation during
the course of language acquisition, the second being a preliminary
investigation to access the validity of the theory by testing
some of the specific hypothesis that it generates. In their
model, it is the left posterior aspect of the brain, at the
junction of the parietal, occipital, and temporal lobes (POT)
that generates semantically relevant, modality-free mental representations
by allowing signals from all neocortically-represented sensory
modalities to converge in a single processing region. In turn,
the linguistically relevant contributions of Brocas area, located
in the inferior portion of the left frontal lobe imparts abstract
structure to those representations with which it interactsincluding
(functional) grammatical components as well as the semantic
components. The idea here is that we can now tentatively spot
functional abstract grammar within the frontal lobe areas of
the brain, and show how such grammatical aspects relate to the
more primitive, prosaic elements of lexical-semantics (as spotted
in the temporal lobe regions). The trick here is to see if the
two regions are initially talking to one another (as in neuro-connectivity),
say at our grammatical stage-1. Using PET/ERP-language studies,
a sketchy two-prong picture emerges suggesting that the neural
mechanism(s) involved split along lexical and functional grammatical
stages of language development. It is clear that Brocas area
is involved not only with the generation of abstract hierarchical
structure, but, with the representation of lexical items belonging
to functional categories. However, the studies reveal that in
order for Brocas area to work at this highly abstract level
of representation, the frontal lobe which houses Brocas area
must also connect to the POT region of the brainin this sense,
a real conversation must be carried out between the (first order)
semantic properties of language (POT) and their functional counterparts.
This relationship parallels the lexical-functional dichotomy
found in all language.
|
|
| 62. |
The W&W study suggests that the maturational
development of language follows from brain developmentand
can be summarized below:
a. The lexical stage-1 of language acquisition naturally
arises from a disconnect between the more primitive POT
(temporal-lobe/lexical-grammar region) and the hierarchical
Brocas area (frontal-lobe/functional grammar).
b.& This disconnect has to do with the biological development
of myelination in the bundle of axons that connect the two
areas together. Myelination of axons is then said to mature
at roughly that chronological stage where we find a lexical
(staged) grammar merging with a functional (staged) grammar.
c. With respect to the brain/language relationships
in the child, it is important to recognize that during the
period of time typically associated with the initial stages
of language acquisition, the brain is still in a relatively
immature state. Neural plasticity begins with the sensory
motor-strip temporal area (POT), and then proceeds to move
to secondary areas (Brocas area) related to the frontal
lobe region.
|
|
| |
Conclusion: A Converging Theories Model
|
| 63. |
In the history of all pursuit of science, it
has traditionally been the case that science precedes and
develops via different methods and theories. Converging approaches
always strive to expose inherent weakness in their opposing
theories. It goes without saying that convergence methods
go far in peeling away biased assumptions which often lead
to half-correct assertions. Taking what is good from one theory
and throwing away what is not is just common-sense science.
For example, on one converging; hand, Chomsky has asserted
that syntax is the result of the creative human brain set-up
in such a way as to manipulate true-rules. It creates, from
nothing external to itself, the structure of language. (See
special nativism above). In restricting ourselves to the point
at hand, Chomsky has assimilated much of his arguments from
the long line of rational philosophy and has converged such
reasoning into how he believes an autonomous language structure
(internal) might be construed. His belief that syntax is autonomous
directly paves a way for him to distinguish between species-specific
(human/hominid) language and other modes of cognitive-based
primitive communications (animal/pongid). His now famous debatesfirst
between Skinner (Behaviorism) and later with Piaget (Constructivism)can
be readily reduced back to Converging Methodologies between
(philosophy and cognition) which sought to return language
to seventeenth century nativist assumptions. Later, he would
go on to extend such arguments to fight off pure pragmatic/socio-linguistic
pursuits of linguisticssaving the study of language from
becoming strictly a humanities field of study which emphasized
social phenomena with little if any analytical worth: (cf.
Quine, Rorty pace Chomsky). Taking his notion of an
autonomous syntax further, the natural next step to take would
be to say that all other aspects of language (whatever they
may be) that cant fall under this autonomous rule-based syntactic
realm might be conversely tethered to both behaviorism and
associationism as part of an underlying cognitive mechanism.
Chomsky has himself expressed the possibility that general
mundane concepts--many of which contain inherent sub-categeorial
features that are extremely convoluted and abstract, yet from
which we go on to readily attach labels (=words)may be preconceived
and innate: however, he goes on to suggest that such conceptual
innateness may be tethered to cognition as a universal ability
to get at meaning (Chomsky 2000: p.61-62):
These conceptual structures appear to yield semantic
connections of a kind that will, in particular, induce an
analytic-synthetic distinction, as a matter of empirical
fact.
These elements (he cites concepts such as locational
nature, goal, source of action, object moved, etc.) enter
widely into lexical structure¼ and are one aspect
of cognitive development.
|
|
| 64. |
On one hand, what Chomsky seems to be saying
is that (i) Functional Grammar, or Syntax (par excellence)
is autonomous and disassociated from all other aspects of
the mind/brain-including meaning and/or cognition. Thus, syntax
is created from out of the minds creative and independent
eye (with all aforementioned nativist trappings). However,
and to the point of this section, Chomsky doesnt hesitate
to attribute those non-syntactic aspects of language, say
word learning (based on frequency learning and associationism,
to cognition. This, I believe, goes to the heart of the matter--namely,
that a form of converging theories has been evoked here and
could be summarized as follows:
Chomsky and Converging Theories
1. Syntax proper (labeled herein as Functional Grammar)
is creatively formed by a true-rule process via an innately
given Language Acquisition Device (LAD) (more recently called
the Language Faculty)comprising of initial grammatical
default settings of which are called Universal Grammar.
For example, this is where the more abstract Inflectional
rules are housed: the functional features of number/person/case/agreement/tense
e.g. Plural [N+ {s}], Past Tense [V+{ed}], etc. Of course,
the Wugs-Test of Berko goes directly under this category.
Meaning is detached from syntax.
2. Word learning (labeled herein as Lexical Grammar) is
formed via a one-to-one iconic association between sound
and meaning. This process of both word learning on (i) a
phonological level, and word learning on (ii) a semantic/conceptual
level, is more akin to past behavioristic notions of learning.
Very young children (at our stage-1) may exploit and over-extend
such processesthis is apparently what we find regarding
formulaic type utterances, Irregular Verb/Noun lexical learning
and retrieval, as well as Derivational morphology.
|
|
| 65. |
Connectionism In
view of Chomskys assertion that Syntax is autonomous, there
can be by definition no primitive lower-level capacities at
work in syntaxnamely, nothing that hinges on perception, sound,
object movement, spatio-temporal, etc. Although we share with
our primates such low-scope abilities, more than anything else,
it is our ability to work with abstract rules which creates
the unsurpassable, and ever widening gap between human language
and animal communicationthe former based on true-rules &
syntax, the latter based on more primitive behavioristic modes
of learning. Regarding the higher-level processes having to
do with syntax/grammar, the bootstrapping problem as discussed
above does provide a way for lower-level processes associated
with connectionism to serve as a springboard for later rule-based
grammar. For instance, it is now widely assumed (cf. Plunkett,
Elman, among others) that something like a connectionist system
most provide the neurological foundations for the apparent symbolic
mind. In other words, a symbol processing system might sit on
top of a connectionist implementation of the neurological system.
Such an heteroarchical layered approach to language would be
similar to stating that in order to talk about Darwinian Biology,
one must first acknowledge the underlying universals of Physics.
However, having said this, and more to the point of Chomskys
reference to autonomous syntax, a symbol processing system would
operate according to its own set of principles. Recently, the
notion of hidden units/rules providing crucial feedback
loops in connectionist processors have been interpreted (much
to the chagrin and potential demise of the pure connectionist
group) as a form of a quasi innate symbolic devise--cleverly
hidden in the actual architecture itself. (See the on-going
debates between Marcus vs. Elman, Elman vs. Marcus on this).
Nonetheless, it is now becoming commonly accepted in connectionist
circles that a number of local architectural constraints are
indeed necessary in order to bring about a sufficiently qualitative
approximation of computation worthy of language: constraints
such as the right number of units (hidden and overt), layers,
types of connections etc. Notwithstanding camp rhetoric and
inevitable spin involveagain, arguments tantamount to the old
nature vs. nurture debate--there however may be something to
the notion that such hidden units serve as a bridge between
the two systems (and for that matter, the two schools of thought).
Moreover, there is a certain degree of truth to the analogy
stating hidden unit tabulations spawn symbolic rule paradigms.
From this dualistic approach, it is possible to tentatively
sketch out some shape of what a Converging Theories Model might
look like in the face of such aforementioned assertions:
|
|
| 66. |

|
|
| 67. |
The above lexical categories are substantive in
meaning and are akin to more behavioristic processes such as
rote-learning, formulaic mimics, frequency-based memorization-as
discussed in a Piaget-style cognitive learning model. The above
functional categories are non-substantive in meaning and are
akin to true autonomous syntactic theory (Chomsky), and the
creative ability to carry out preconceived rules with novel
items (Brown, Berko). From a neurological standpoint however,
Chomskys idea of an autonomous syntax is treated as a quintessential
impossibility-the obvious being that--there must be a syntax
positioned in the brain, and thus buttressed by any or all cognitive
apparatus. Our Converging Theory Model as sketched above partially
gives this argument to the neuro-science position by claiming
that indeed one aspect of language is tethered to a low-scope
cognitive apparatus. Where we beg to differ is that higher-scope
rule-driven processes are not cognitive bound and rather rely
on their own set of structure dependency conditions to survive--a
structure dependency that has no bearing on the exterior cognitive
realm. This analogy follows in the wake of Steven Pinkers hypothesis
stating that a dual mechanism of language is at work in language
acquisition(i) one based on cognitive universal in relation
to the lexical component of the brain (say, our stage-1 child
grammar), and (ii) one based on true-rule formation related
to the computational component of the brain (say, our stage-2
child grammar). (Recall our brief discussion on Radford (§19ff)
in defining a functional stage-2 grammar based on pure syntactic
(high-scope) [+/-Interpretable features).
|
|
| 68-69 |
A Final note
|
| 70 |
References (In Preparation)
|
| |
Back
to Index >>
[1] [2] |
|