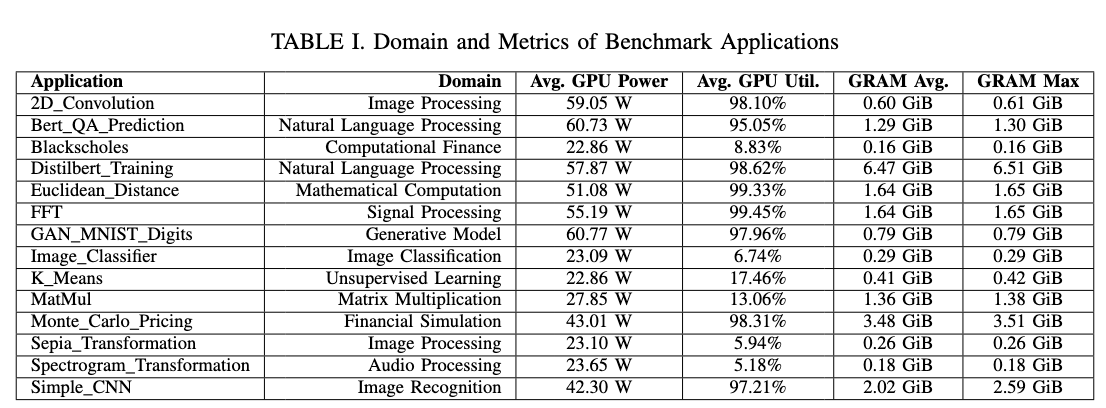
GPU Temperature Model
Problem
Given sequential data across several hours containing information about the computational load of a given computer server, predict the GPU temperature of the server at every second in the sequence.
Data Collection
To understand real-world usage, we analyzed the resource demands and arriving time intervals between task requests of a real datacenter (DC) Analysis of real-world data center workload traces indicated that tasks execution time and requested resources varied
- We simulated GPU usage under a diverse set of tasks with random task arriving time within specified ranges to mimic traffic patterns.
- We run a series of GPU-intensive benchmarks with various use cases including machine learning, image processing, financial modeling, etc.
- A service was launched to track the CPU, GPU, RAM, and disk utilization and temperature.
- Our premise in data collection was to capture the full spectrum of GPU behavior under different task arriving intervals.
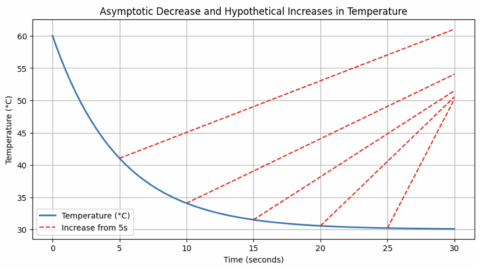
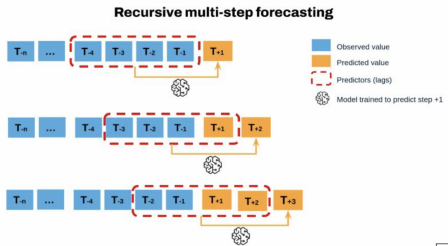
Figure 2. Hypothetical behaviour of GPU temperature. Figure 3. Recursive Multi-step Forecasting Process[3].
Recursive multi-step forecasting
- The sequential nature of the data means that temperatures are closely related to adjacent values.
- Our models leverage either a lagged input or sliding window approach to capture these temporal dependencies.
- The window-based models used all data from the n previous time steps for an input shape of nxm, with n being window size and m being # of features.
- Tested 6 model architectures: Long Short-Term Memory (LSTM), XGBoost, CatBoost, LightGBM Transformer, and a hybrid CNN-LSTM model.
Scheduled Sampling
An issue that came up was accuracy for time series forecasting:
- Teacher forcing: In training, models accessed the real temperature from previous time steps, causing an overreliance on lagged features. In prediction, models only accessed the generated temperature of previous time steps, leading to compounding error.
- Scheduled Sampling (SS): Gradually transition from using the correct output (target sequence) as inputs to using the model's own predictions. This method made the model more robust to mistakes during inference, as it learned to rely on lag features less.
- With scheduled sampling, we reduced RMSE by over 50% across all models
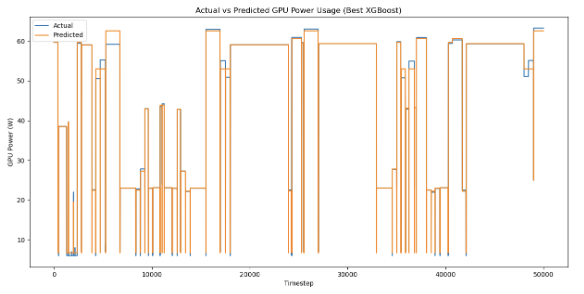
Through the testing of new model architectures, scheduled sampling training, and extensive hyperparameter tuning, we reduced the RMSE from the existing temperature model by an estimated 90%.
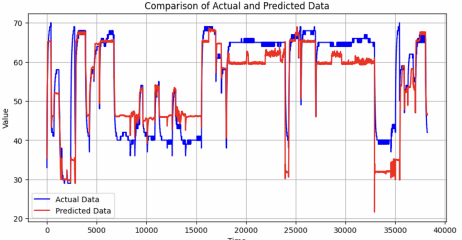
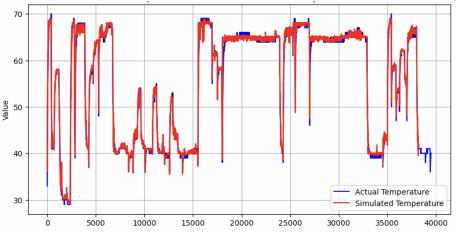
Figure 4. Actual vs. Simulated temperature by an initial model. Figure 5. Actual vs Simulated temperature by scheduled sampling-trained hybrid model.