
Experimental Results
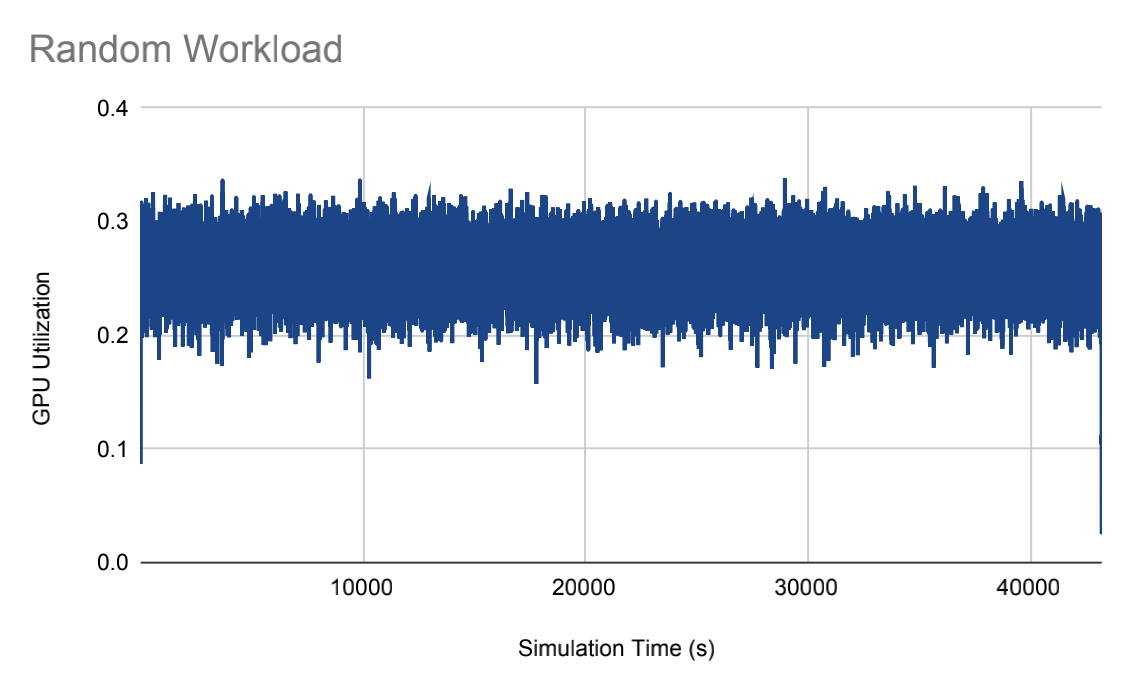
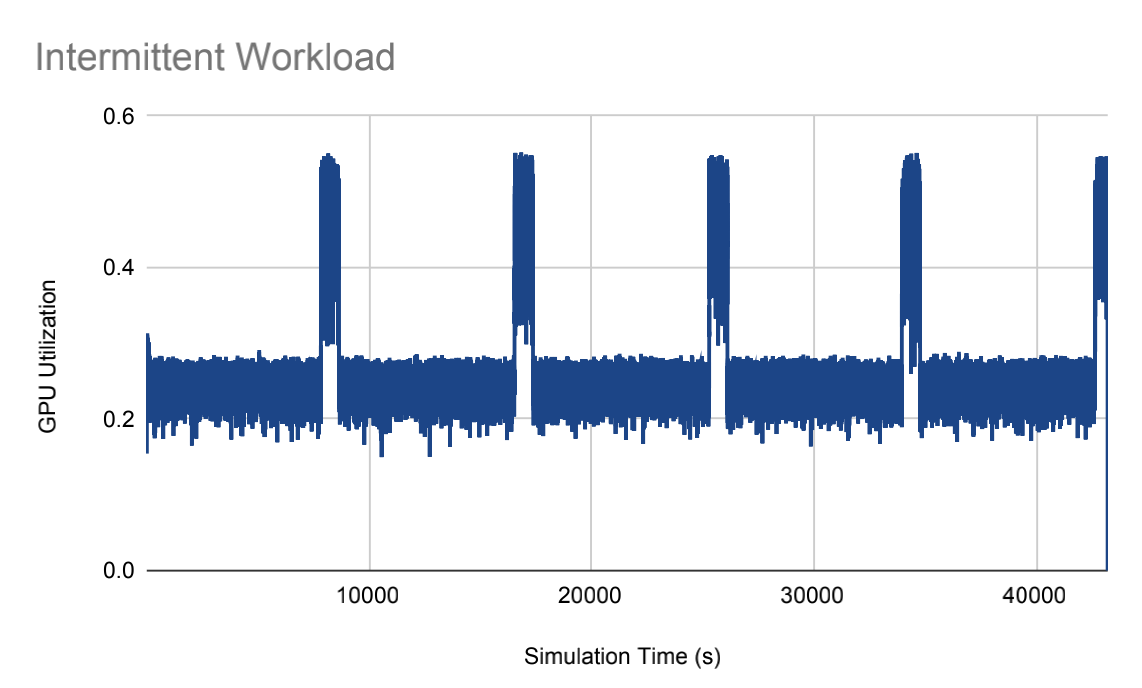
To replicate real-world workloads found in data centers, three common patterns of data traffic were utilized: random, intermittent (bursty), and periodic.
 |
 |
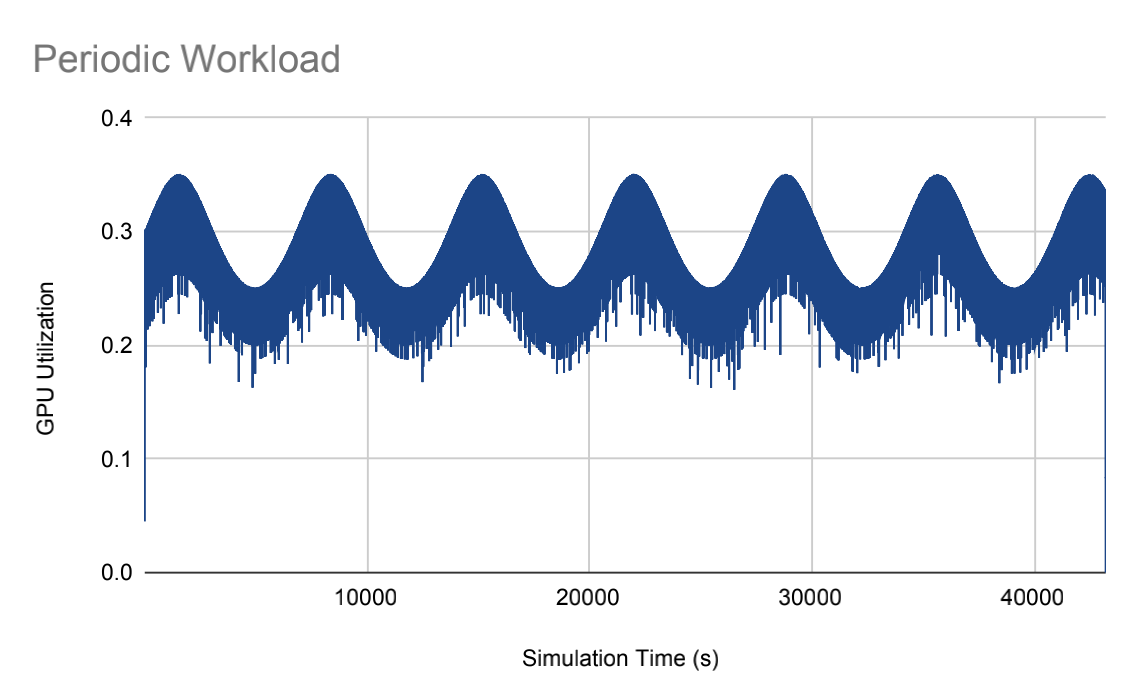 |
| Figure 2. Random Workload. | Figure 3. Intermittent Workload. | Figure 4. Periodic Worklod. |
(Figures 2~4 were created by Luke Zhao.)
We simulated a data center of four hosts, with each host having 20 CPU cores and 500 GPU cores. Each host had five virtual machines with 5 CPU cores (5,000 MIPS capacity) and 100 GPU cores (50,000 MIPS capacity) allocated to them. GpuCloudlets were sent in batches every second by a workload generator. After one simulated hour, GpuCloudlets were no longer submitted to the data center. The time obtained from the simulator, when all submitted applications have finished processing, is the simulated runtime. Three machine learning models were used for computing cost power prediction for GPU servers: (1) Model 1: XGBoost CPU Temperature Model takes time (in seconds) and CPU utilization as inputs[3]; (2) Model 2: XGBoost GPU Power Model takes GPU temperature, GRAM utilization, GPU utilization, CPU temperature, and CPU utilization as inputs; and (3) Model 3: XGBoost GPU Temperature Model takes GPU power, GRAM utilization, GPU utilization, CPU temperature, and CPU utilization as inputs. (Model 2 and 3 were built by Rachel Finley.)
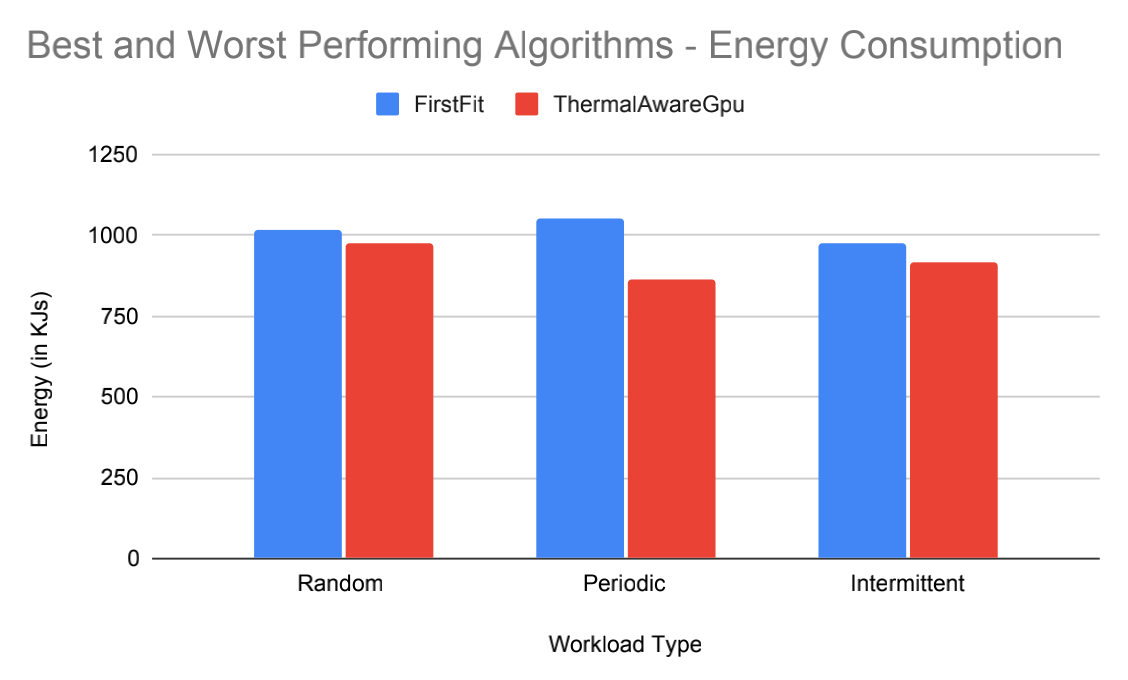
Figure 4. The energy consumption for the ThermalAwareGpu and FirstFit algorithms, for all workload types.
(Figure 4 was created by Matthew Smith.)
Conclusion and Future Work
Simulation data was collected for each combination of workload type and GpuDatacenterBroker. The simulated computing energy (CPU and GPU combined) for the best and worst algorithms is shown. We observed that both ThermalAware algorithms had significant energy savings with runtimes equivalent or faster (3 seconds) than the built-in algorithms, for all workload types. In the future, we will: (1)Estimate datacenter cooling energy and compare algorithms; (2) Create new workload types and algorithms; (3) Use real-world datacenter simulation parameters: Hosts/Vms; (4) Increase the intensity of the simulation; and (5) Improve CPU/GPU utilization models.
Reference
[1] Shashikant Ilager, Kotagiri Ramamohanarao, and Rajkumar Buyya. “Thermal Prediction for Efficient Energy Management of Clouds Using Machine Learning”. In: IEEE Transac- tions on Parallel and Distributed Systems 32.5 (2021), pp. 1044–1056. DOI: 10 . 1109 / TPDS.2020.3040800.
[2] J. D. Moore et al. “Making Scheduling "Cool": Temperature-Aware Workload Placement in Data Centers”. In: USENIX Annual Technical Conference, General Track. Apr. 2005, pp. 61–75.
[3] Icess Nisce, Xunfei Jiang, and Sai Pilla Vishnu. “Machine Learning based Thermal Pre- diction for Energy-efficient Cloud Computing”. In: 2023 IEEE 20th Consumer Communica- tions & Networking Conference (CCNC). 2023, pp. 624–627. DOI: 10.1109/CCNC51644. 2023.10060079.
[4] Arman Siavashi and Mohammad Momtazpour. “GPUCloudSim: An Extension of CloudSim for Modeling and Simulation of GPUs in Cloud Data Centers”. In: Journal of Supercomputing 75 (2019), pp. 2535–2561. DOI: 10.1007/s11227-018-2636-7.
[5] Manoel C. Silva Filho et al. “CloudSim Plus: A cloud computing simulation framework pursuing software engineering principles for improved modularity, extensibility and correct- ness”. In: 2017 IFIP/IEEE Symposium on Integrated Network and Service Management (IM). 2017, pp. 400–406. DOI: 10.23919/INM.2017.7987304.
Acknowledgements
This project is supported by the National Science Foundation under Grant CNS-2244391.