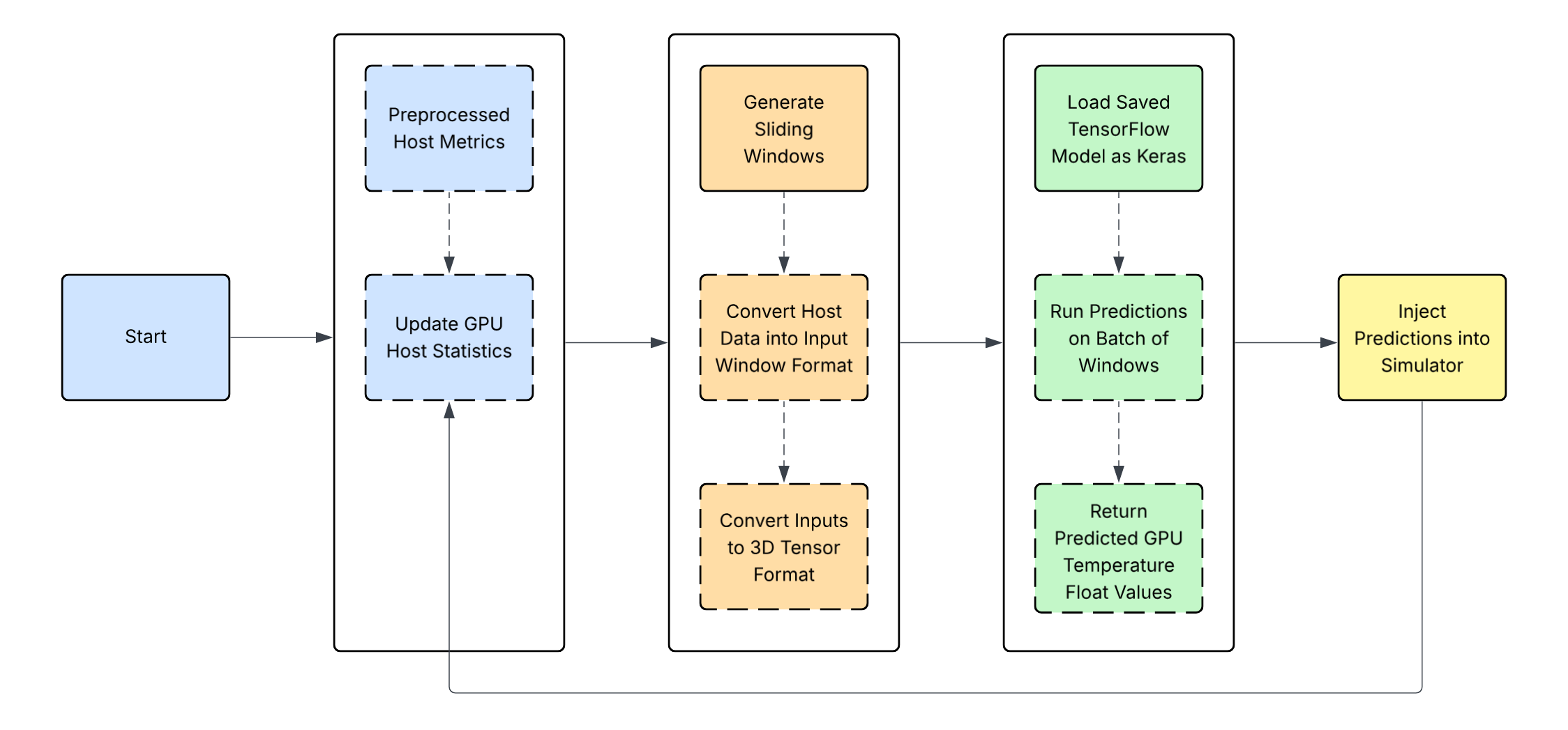
GPU Temperature Model
Problem
Given sequential data across several hours containing information about the computational load of a given computer server, predict the GPU temperature of the server at every second in the sequence.
Model Building Approach
To understand real-world usage, we analyzed the resource demands and arriving time intervals between task requests of a real datacenter (DC) Analysis of real-world data center workload traces indicated that tasks execution time and requested resources varied.
- Implement Baseline models (e.g., CNN-BiLSTM, Transformer, Informer, PatchTST, Pathformer, XGBoost) without optimization
- Create variants using scheduled sampling, attention forcing, and physics-informed losses
- Export models to ONNX and evaluate autoregressively (AR) in a Java environment.
- Check integrity by comparing ground-truth-based outputs cross-platform
- Training and inference times, power consumption, and predictions were recorded.
- Analyze results using the Friedman test, followed by Wilcoxon tests with Bonferroni correction
Friedman Test: Detected a difference in model performance (p-value: 0.0001})
Input Window Size: Window sizes of 3-50 tested on all models; 5 resulted in best AR RMSE
Input Features: CPU Average Temperature, CPU Average Utilization, GPU Average Utilization,
GPU Average Power (W), GPU GRAM Average (gib), GPU temperature
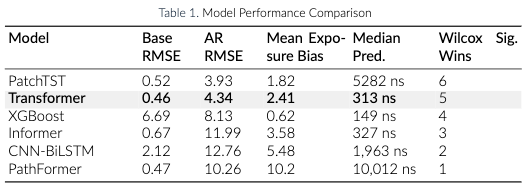
Table I shows the comparison of the model performance for baseline models. Figure 1 and 2
show the comparison of GPU prediction using ground truth values, autoregressive, and non-autoregressive approach with Transformer model and the CNN-BiLSTM model.
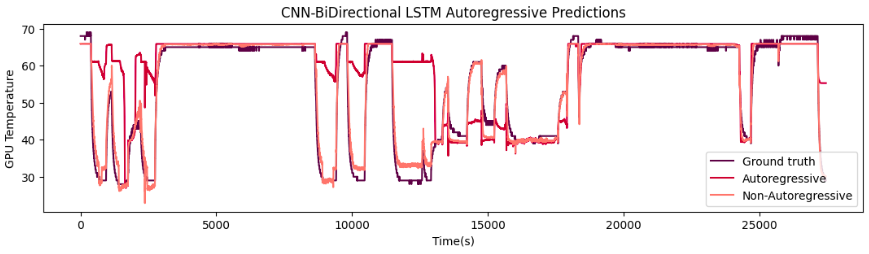
Figure 1. Transformer GPU Temperature predictions Figure 2. CNN-BiLSTM GPU Temperature predictions